Organise Microdata for Social Scientist
Data Confidentiality, Data Security and Data sensitivity are two important consideration but should not be confused.
- Data Confidentiality is linked to data protection and can be addressed through anonymisation.
- Data Security is dependant from technical processes that needs to be established to prevent leaks.
- Data Sensitivity is tied a collective clearance and information classification process.
Once those elements are addressed, it becomes possible to engage with researchers.
Dealing with confidentiality
Once anonymised, a dataset does not fall anymore under the Policy on the Protection of Personal Data.
Anonymization techniques
Even when personal data is not being collected it still may be appropriate to apply the methodology since quasi-identifiable data or other sensitive data could lead to personal identification or should not be shared.
| Type | Description |
|---|---|
| Direct identifiers | Can be directly used to identify an individual. E.g. Name, Address, Date of birth, Telephone number, GPS location |
| Quasi- identifiers | Can be used to identify individuals when it is joined with other information. E.g. Age, Salary, Next of kin, School name, Place of work |
| Sensitive information | & Community identifiable information Might not identify an individual but could put an individual or group at risk. E.g. Gender, Ethnicity, Religious belief |
| Meta data | Data about who, where and how the data is collected is often stored separately to the main data and can be used identify individuals |
The following are different generic anonymisation actions that can be performed on sensitive fields. The type of anonymisation should be dictated by the desired use of the data. A good approach to follow is to start from the minimum data required, and then to identify if any of those fields should be obscured.
The methods below can be referenced in the dedicated column within xlsform (cf above)
| Type | Description |
|---|---|
| Remove | Variable is removed entirely from the data set. The Variable is preserved in the original file. |
| Reference | Variable is removed entirely from the data set and is copied into a reference file. A random unique identifier field is added to the reference file and the data set so that they can be joined together in future. The reference file is never shared and the Variable is also preserved in the original file. |
| Mask | The Variable values are replaced with meaningless values but the categories are preserved. A reference file is created to link the original value with the meaningless value. Typically applied to categorical Variable . For example, Town names could be masked with random combinations of letters. It would still be possible to perform statisitical analysis on the Variable but the person running the analysis would not be able to identify the original values, they would only become meaningful when replaced with the original values. The reference file is never shared and the data is also preserved in the original file. |
| Generalise | Continuous Variable is turned into categorical or ordinal Variable by summarising it into ranges. For example, Age could be turned into age ranges, Weight could be turned into ranges. It can also apply to categorical Variable where parent groups are created. For example, illness is grouped into illness type. Generalised Variable can also be masked for extra anonymisation. The Variable is preserved in the original file. |
Statistical disclosure control (SDC)
Though there’s a few articles about the failure of anonymization that shows how removing names & ID is not always sufficient to prevent “data re-identification”.
Many techniques can be used for “statistical disclosure control”: suppression, inference control, banardisation, rounding or sampling. Other approaches includes rules like for instance “do not share figures for a spatial unit if it does not reach the 1000 refugees threshold”…
A dedicated R module is available to perform anonymisation analysis.
Ensuring data security
Access Registry
A first requirement is to set up a standard registry of person who work on UNHCR datasets. This is actually prescribed in the data protection policy.
Sharing via a safe mechanism: File encryption
What is a safe mechanism to share information: for instance which software to use for encryption, how to share password, etc. Potential requirements could include: - Use a well know encryption approach – The common standard si AES -Advanced Encryption Standard (AES) - Rely on open source software – so both parties can easily encrypt & decrypt without being tied to software procurement obstacle. - Combine encryption and file compression: so files are easier & lighter to share - The password used for the encryption should be at least 10 character long with a mixture of lowercase and uppercase alphabetic character, numbers and symbols. This should allow to build what is commonly called a strong password and should always be transmitted independently form the file (for instance on a separate paper sheet with no reference to the file it allows to open).
In terms of software, it is possible to use 7zip.
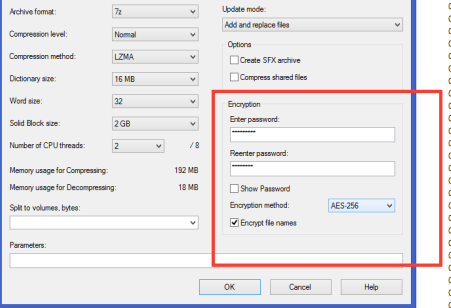
A summary of the principle above woud be:
Data files should be encrypted with AES-256 method using a strong password (at least 10 character long with a mixture of lowercase and uppercase alphabetic character, numbers and symbols) and compressed using the 7zip format with the 7zip software. Password will be transmitted printed on a paper that will need to be secured by the receiving agency.
Dealing with sensitive information
Information classification
Sensitive Data - institutional data that is not legally protected, but should not be made public and should only be disclosed under limited circumstances. Users must be granted specific authorization to access since the data’s unauthorized disclosure, alteration, or destruction may cause perceivable damage to the institution.
Data sharing for research
If outsourced, formal agreement needs to established.
The UNHCR and Partner Name will identify the staff to be part of the joint research team. Any data shared under this agreement will not be provided to any third party. For its part, UNHCR agrees to share defined and agreed upon data with the Partner Name for the purposes of the Partner Name and UNHCR collaboration on this project herein-defined as “Project Name”. All information that would allow for identification of individuals will be excluded from these datasets, e.g. refugee ID number. UNHCR will share this information via a safe mechanism to reduce the likelihood of a third party accessing the data unlawfully. Partner Name will specify by name and title who will receive the information, who will have access to the information, and where the information will be kept, e.g. individual personal computer or server, all with the intent to avoid unlawful access and use of the information. Once the information is used for its defined purpose, the data will be disposed of at a date determined and in agreement by the two parties.
Restricting publication of findings
Research Confidentiality agreement are written and legally-binding Confidentiality Agreement that must be signed by the lead researcher, all members of the research team that will have access to individually identifiable information from the records. The agreement coudl include the following points:
Analysis Project Title Principal Investigator: UNHCR
I, Resesarcher Name, from Resesarch Organisation Name, as a member of this research team, understand that I may have access to confidential information about study sites and participants. By signing this statement, I am indicating my understanding of my responsibilities to maintain confidentiality and agree to the following:
keep all the research information shared with me confidential by not discussing or sharing the research information in any form or format (e.g., disks, tapes, transcripts) with anyone other than the Researcher(s).
keep all research information in any form or format (e.g., disks, tapes, transcripts) secure while it is in my possession.
return all research information in any form or format (e.g., disks, tapes, transcripts) to the Researcher(s) when I have completed the research tasks.
after consulting with the Researcher(s), erase or destroy all research information in any form or format regarding this research project that is not returnable to the Researcher(s) (e.g., information stored on computer hard drive).
notify the local principal investigator immediately should I become aware of an actual breach of confidentiality or a situation which could potentially result in a breach, whether this be on my part or on the part of another person.
Engaging in research
Reproducible research
To ensure that research done on the dataset can be reproduced afterwards by internal staff both to check them and to refresh the analysis when we have new data a series of good practices shoudl be implemented:
For every result, keep track of how it was produced
Avoid manual data manipulation steps
Archive the exact versions of all external programs used
Version control all custom scripts
Record all intermediate results, when possible in standardized formats
For analyses that include randomness, note underlying random seeds
Always store raw data behind plots
Generate hierarchical analysis output, allowing layers of increasing detail to be inspected
Connect textual statements to underlying results
Provide public access to scripts, runs, and results
Establish a survey catalog
Humanitarian Research in the context of social science and data analysis is still new but can benefit the organisedtion for instance to:
- Co-development and co-design of tools, protocols, products, processes, and innovations
- Facilitate organisational learning, keeping track of lessons learned, and providing a neutral stance for moderating innovation and change processes
- Access to wider body of knowledge, from academia or other organisations, and research in other fields.
To facilitate this process, the first approach woudl be to document the dataset according to the Data Documentation Initiative (DDI) metadata standard developped by the International Household Survey Network (IHSN).
Once the metadata are generated in the right format, it becomes possible to publish them within the ISHN Microdata catalog or the World Bank Microdata Library