## Loading the stat tables
lastyear <- max(unhcrdatapackage::end_year_population_totals_long$Year)
data <- dplyr::left_join( x= unhcrdatapackage::end_year_population_totals_long,
y= unhcrdatapackage::reference,
by = c("CountryAsylumCode" = "iso_3")) %>%
filter(Population.type == "REF" & Year == lastyear & !(is.na(UNHCRBureau))) %>%
group_by(Year, CountryAsylumName, CountryAsylumCode, UNHCRBureau ) %>%
summarise(Value2 = sum(Value) )
#> `summarise()` has grouped output by 'Year', 'CountryAsylumName', 'CountryAsylumCode'. You can override using the `.groups` argument.
# Population, GDP & GNP per Capita from WorldBank
wb_data <- wbstats::wb( indicator = c("SP.POP.TOTL", "NY.GDP.MKTP.CD", "NY.GDP.PCAP.CD", "NY.GNP.PCAP.CD"),
startdate = 1951, enddate = 2020, return_wide = TRUE)
#> Warning: `wb()` was deprecated in wbstats 1.0.0.
#> Please use `wb_data()` instead.
# Renaming variables for further matching
names(wb_data)[1] <- "CountryAsylumCode"
names(wb_data)[2] <- "Year"
wb_data$Year <- lastyear
df2 <- merge(x = data, y = wb_data, by = c("CountryAsylumCode" ,"Year"), all.x = TRUE)
df2 <- df2[ !(is.na(df2$UNHCRBureau)) & !(is.na(df2$NY.GNP.PCAP.CD)) , ]
df2$prop <- df2$Value2 / df2$SP.POP.TOTL
stacked_df1 <- df2 %>%
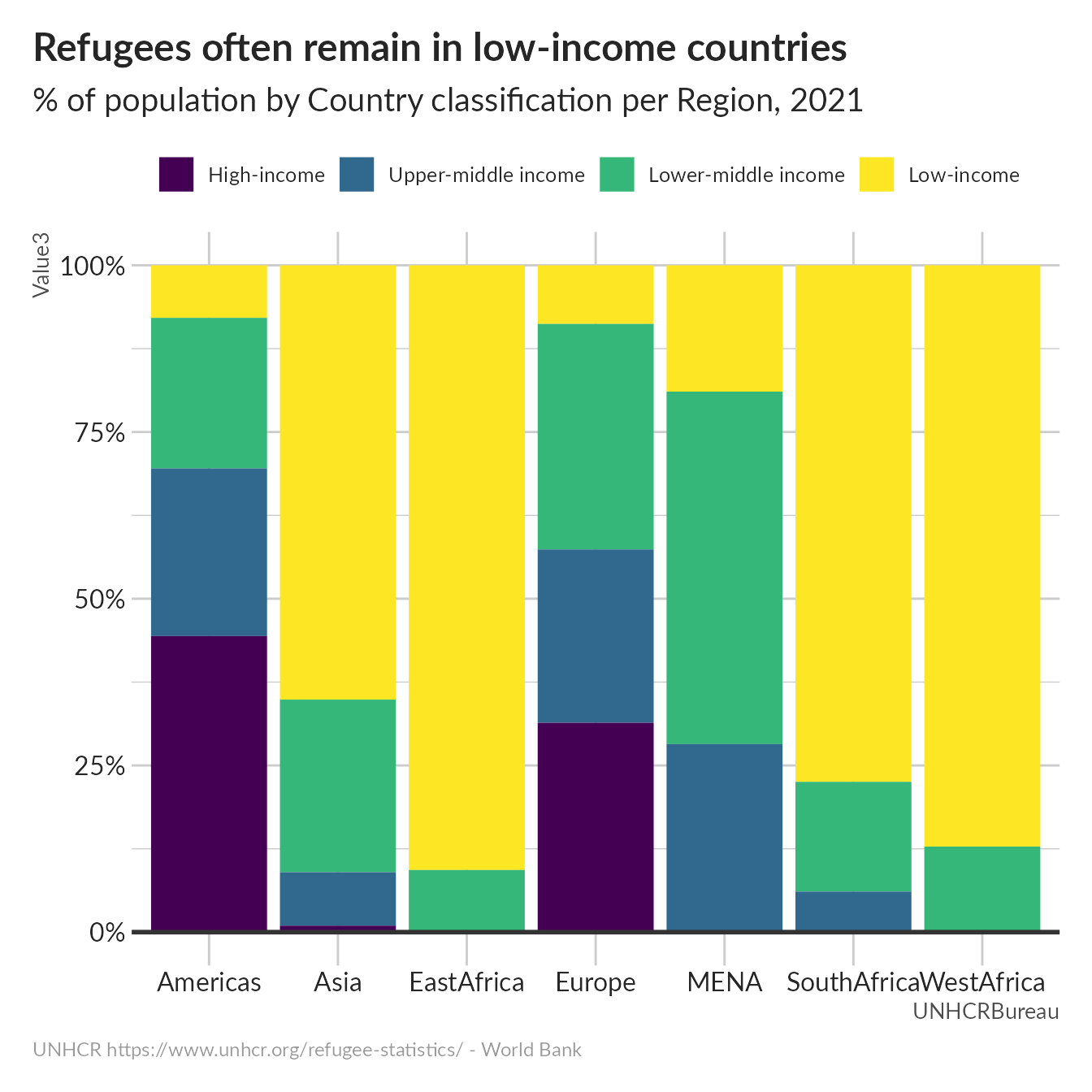
mutate(CountryClass = cut(NY.GNP.PCAP.CD,
breaks = c(0, 1005, 3955, 12235, 150000),
labels = c("Low-income", "Lower-middle income", "Upper-middle income", "High-income"))) %>%
group_by(UNHCRBureau, CountryClass) %>%
summarise(Value3 = sum(as.numeric(Value2)))
#> `summarise()` has grouped output by 'UNHCRBureau'. You can override using the `.groups` argument.